Our main priority is always the quality of the data we provide to the EVN users.
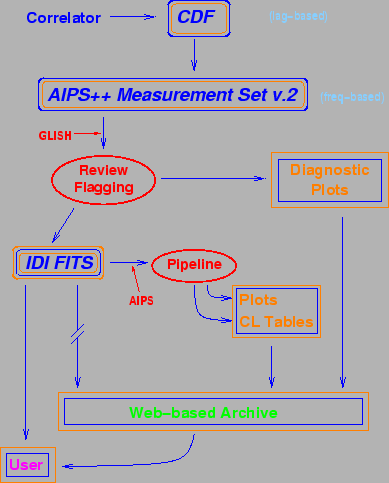
Our internal data review process, as shown in Figure 3, begins by transforming
the lag-based correlator
output into AIPS++ Measurement Sets (MS).
This MS contains a data-cube of the real & imaginary components of the
correlation-function
spanning, for each subband of each baseline/autocorrelation,
![]() ,
, ![]() , and
, and ![]() (or
(or ![]() , if
the need arises).
We can then investigate, using the glish language, slices of the
correlation functions in both time and frequency/lag, allowing us to
detect and diagnose various problems with the recorded data or the correlation
itself, and to determine any scans for which recorrelation would be profitable.
We can also make various plots more suited to providing feedback to the
stations rather than to the PI (e.g., parity-error rates, sampler
statistics).
We apply various corrections to the correlated data at this stage
(e.g., the 2-bit van Vleck compensation, cf §2.4).
We also flag subsets of the data for low
weights and other known problems resulting in (uncorrectable) spurious
correlation amplitudes
and/or phases.
, if
the need arises).
We can then investigate, using the glish language, slices of the
correlation functions in both time and frequency/lag, allowing us to
detect and diagnose various problems with the recorded data or the correlation
itself, and to determine any scans for which recorrelation would be profitable.
We can also make various plots more suited to providing feedback to the
stations rather than to the PI (e.g., parity-error rates, sampler
statistics).
We apply various corrections to the correlated data at this stage
(e.g., the 2-bit van Vleck compensation, cf §2.4).
We also flag subsets of the data for low
weights and other known problems resulting in (uncorrectable) spurious
correlation amplitudes
and/or phases.
The last step converts the final MS into FITS format, usually written to
a DAT tape. We send this to
the PI, along with a summary of the correlation itself. The FITS DAT can
can be read into AIPS directly using FITLD.
We also make
various diagnostic plots available to the PI.
The EVN pipeline operates on the FITS
data to create the first few AIPS CL tables (e.g.,
![]() -based amplitude calibration, off-source flagging, etc.),
which put the data in a state that the PI can use more easily. Plots,
summaries, and pipeline results also go to the EVN archive (accessible
via www.jive.nl/archive/scripts/fits/listfits.php).
The FITS files themselves, subject to release policies that are still under
review, will also be available from this archive.
-based amplitude calibration, off-source flagging, etc.),
which put the data in a state that the PI can use more easily. Plots,
summaries, and pipeline results also go to the EVN archive (accessible
via www.jive.nl/archive/scripts/fits/listfits.php).
The FITS files themselves, subject to release policies that are still under
review, will also be available from this archive.